前置知识
哈哈,简单到爆,没有。
引入
并查集是一种快到爆炸的集合算法,可以进行两项基本操作:合并两个集合(并)、查询两个参数是否在一个集合内(查)。这也是它名字的由来。
速度
他有多快呢?
\(O(*\log n)\)
\(*\log\)有多可怕: |\(n\)|\(*\log n\)| |-|-| |\((1,2]\)|\(1\)| |\((2,4]\)|\(2\)| |\((4,16]\)|\(3\)| |\((16,65536]\)|\(4\)| |\((65536,2^{65536}]\)|\(5\)| 所以n是\(2^{65536}\)的时候复杂度还只有5。 \(2^{65536}\)有19729位。想通了吧?
如何实现
这么高端的算法,是怎么实现的呢?
其实:它的本质就是一个数组 f[],和一个函数 getf()
f[] 存的实际上就是几棵树。
f[i] 就是 i 的父亲。
getf(i) 做的操作就是递归顺着 f[i] 找 i 所在的树的根。
getf() 代码:
1 | int getf(int x){ |
合并就是把两棵树的根节点认作父子关系,查询就是看两个点的根节点相不相同。这么看来,复杂度也不是很低,不过让我们看接下来的:
emmmmm
优化
我们首先随机造出一些操作:
1 | 10 |
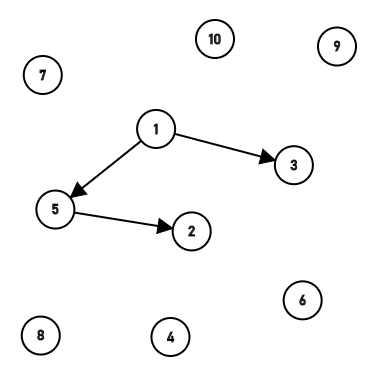
把所有的操作都做完,就形成了这样一个繁杂的森林,要找到一个点的根,就需要走很长一段路。这就拉长了时间。
为了缩减时间,优化就出现了:路径压缩。 路径压缩其实也很简单:在\(getf()\)查找根节点的同时,把自己也链接到根节点上,使得树的深度不超过2。 代码:
1 | int getf(int x){ |
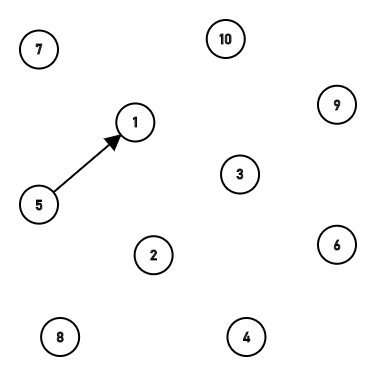
getf()函数运行的同时,f[x]的值也被改变了。我们都知道getf()寻找的是根节点,所以就把x链接到了自己的根节点上。和之前的代码相比,只改了一个地方,就让时间大大压缩。 这时我们再次模拟一下。 第一次合并:
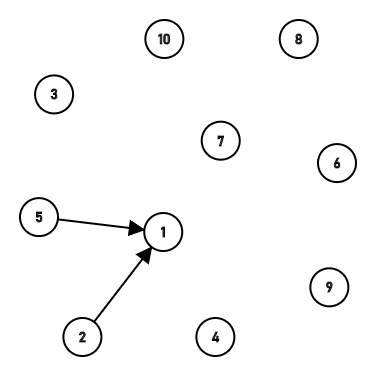
第二次合并时,首先寻找2,5两个节点的根节点,2的根就是2,5的根是1,于是直接把2链接到1上。
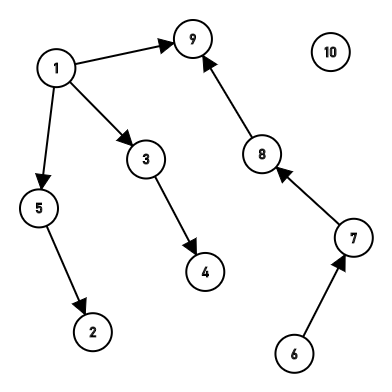
第三次,第四次合并把3链接到了1上,然后把4顺着3也链接到了1上,第五次连接了6和7。
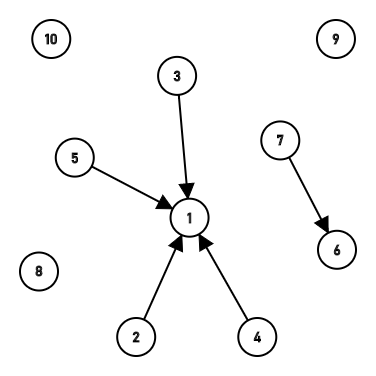
第七次第八次链接成了\(9\rightarrow8\rightarrow7\rightarrow6\)一长串,然后经过路径压缩都链接到6上了。
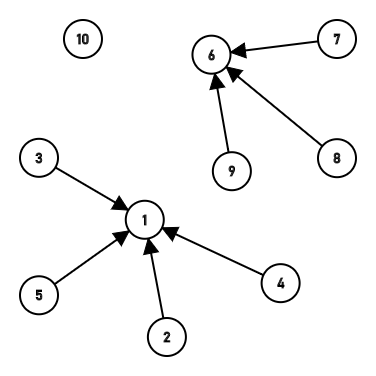
最后一次,把9和1链接起来了,这时深度又超过了2,一下还压缩不下去,不过没关系,查询的时候就会把它压缩的。
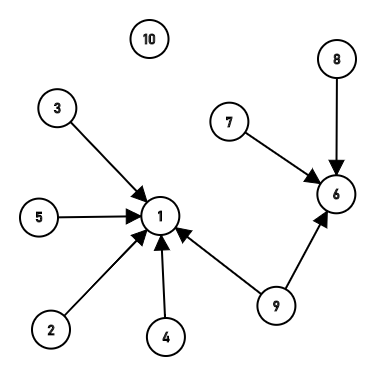
比如查询7和4的时候就会分别寻找7和4的根节点,一路递归找上去的时候就直接把路径压缩好了,除了8还链接在6上,其他全部链接到1上了。
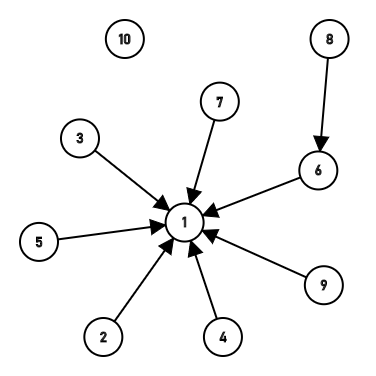
多么有趣啊!
代码
自己想去吧,核心代码和思路都给出来了。 有一个巨大的坑,就是f[i]要预设成i,不然会爆炸。 加油!