We all know computers, and we basically know how to use it, but we have no idea about how does it work.
Well…
If I can present well, and you can understand well, We can watch a video!
Deep inside the computer
Inside the computer, there are loads of parts, and the most important one is the CPU(Central Processing Unit).
The CPU contains basic modules, which contains logic gates, which contains transistors.
Transistor
What is a transistor? Transistor is the most basic part of a computer. It is just an electronic switch, but without it, your computer cannot compute anything.
The transistor has three pins, collector, base, and emitter, also, C, B, E for short. You must be familiar with this because we’ve met it before. Transistor processes information and the information is called BITS, which can be set to either 0 or 1.
Logic Gate
Combining transistors, you will get logic gates, which can get some input and create some output. For example, an AND gate produces an output of 1 if all its inputs are one, and output of 0 otherwise.
Compute Modules
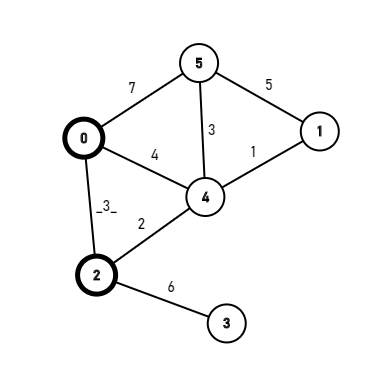
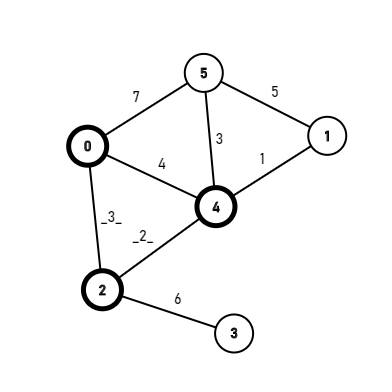
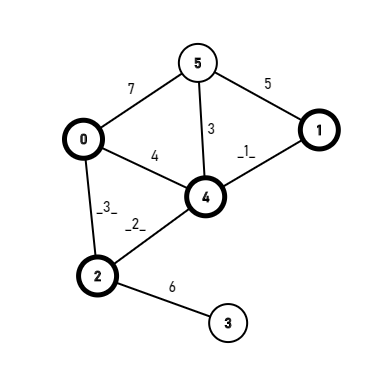
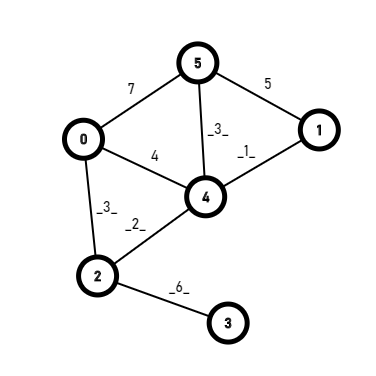
Combining logic gates, you will get compute modules, which can do some basic calculating, such as a+b(a<3,b<3).
Breaking change
Once you can add small numbers, you can add multiple times to add big numbers. And once you can add, you can also multiply, once you can multiply, you can basically do anything.